
不更新参数就能强化学习!OpenAI翁家翌提出新范式:决策只需AI手搓一个.py 文件
不更新参数就能强化学习!OpenAI翁家翌提出新范式:决策只需AI手搓一个.py 文件没有训练梯度的AI,打破了Atari游戏满分纪录。OpenAI核心研究员翁家翌提出了一个强化学习新范式——启发式学习(Heuristic Learning, HL)。
来自主题: AI技术研报
7908 点击 2026-05-09 16:19
 搜索
搜索
没有训练梯度的AI,打破了Atari游戏满分纪录。OpenAI核心研究员翁家翌提出了一个强化学习新范式——启发式学习(Heuristic Learning, HL)。
最近,视频会议软件公司 Zoom 发布了一条出人意料的消息:他们宣称在“人类最后的考试”(Humanity s Last Exam,简称 HLE)这个号称当前 AI 领域最具挑战性的基准测试上,取得了 48.1% 的成绩,比此前由 Google Gemini 3 Pro(带工具)保持的 45.8% 高出 2.3 个百分点。
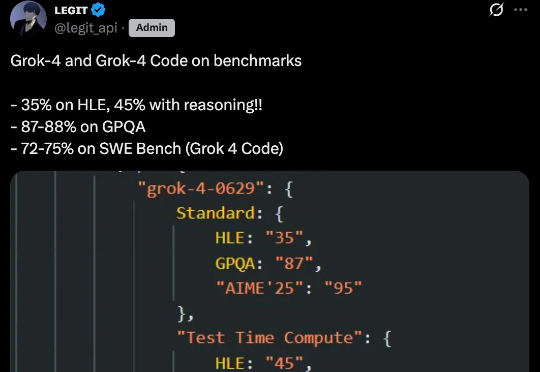
刚刚,Grok 4 和 Grok 4 Code 的基准测试结果疑似泄露。X 博主 @legit_api 发帖称,Grok 4 在 HLE(Humanities Last Exam,人类最后考试)上的标准得分是 35%,使用推理技术后提高到 45%;在 GPQA 上的得分是 87-88%;而Grok 4 Code 在 SWE Bench 上的得分则达到 72-75%。